

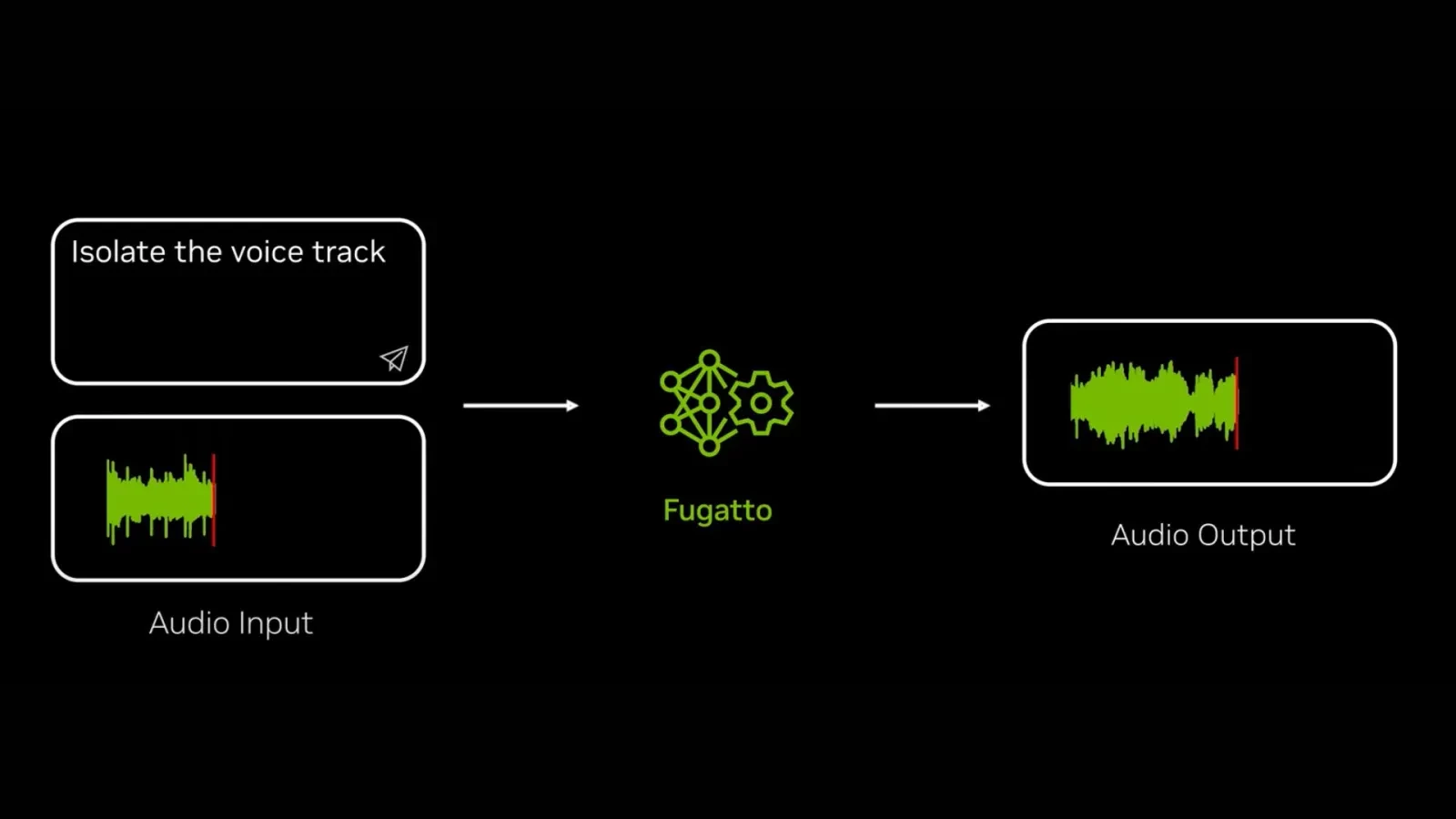
Виробник чипів Nvidia презентував «швейцарський ніж для звуку» — свою нову модель штучного інтелекту, яка може генерувати або редагувати звуки, промову чи музику за допомогою тестових підказок. Її назвали Fugatto, скорочено від Foundational Generative Audio Transformer Opus 1.
У Nvidia стверджують, що хоча деякі ШІ-моделі вже вміють складати пісні або змінювати голос, жодна з них не мають такої спритності, як їхня нова розробка. Менеджер з прикладних аудіодосліджень компанії Рафаель Валле сказав, що розробники «хотіли створити модель, яка розуміє та генерує звук так, як це робить людина».
Що цікавого пропонує Fugatto
Йдеться, що нова модель американського виробника чипів може згенерувати будь-який звук на основі текстової підказки. Nvidia особливо пишається тим, що це може бути реально будь-який звук, який тільки можна описати. Наприклад — гавкання труби чи нявкання саксофона.
«Крім того, на відміну від більшості моделей, які можуть лише відтворювати навчальні дані, Fugatto дозволяє користувачам створювати звукові ландшафти, яких вони ніколи раніше не бачили. Наприклад, грозу, що переходить у світанок зі співом птахів», — кажуть розробники.
Nvidia записала відео, де наочно показала можливості Fugatto. Модель вміє не тільки генерувати звуки, а й редагувати. Наприклад, її можна попросити додати до записаної аудіодоріжки якийсь інструмент, відділити вокал від музики, або сказати фразу з різним акцентом і настроєм.
Поки не ясно, для кого та коли ця модель стане доступною. Але Nvidia вже наводить різні сценарії, де Fugatto може бути корисною різним професіоналам:
- музичним продюсерам, щоб швидко зробити прототип пісні чи поекспериментувати із жанром, голосом та інструментами.
- рекламним агентствам, щоб таргетувати рекламу для різних регіонів або ситуацій, застосовуючи різні акценти та емоції в тексті.
- розробникам відеоігор, щоб модифікувати заздалегідь записані матеріали відповідно до динаміки гри, або ж створювати новий контент у реальному часі.
- Або ж для персоналізації інструментів для вивчення іноземних мов. Наприклад зробити курс, який буде звучати голосом друга чи члена родини.
Технічні характеристики
Fugatto базується на попередніх напрацюваннях команди в таких сферах, як моделювання мовлення, аудіокодування та аудіорозуміння. Повна версія використовує 2,5 мільярда параметрів і була навчена на банку систем NVIDIA DGX з 32 графічними процесорами NVIDIA H100 Tensor Core.
Йдеться, що над новою моделлю працювали фахівці з усього світу. А одна з найскладніших частин роботи — це було створення змішаного набору даних, який містить мільйони аудіозразків, що використовуються для навчання.






